(Source: dba-oracle.com)
This paper is by no means an exhaustive discussion on RAC or its architecture. The focus here is only on the concept called CACHE FUSION which is core to the functioning of a RAC setup. The intention is that after reading the paper, readers should be well acquainted with CACHE FUSION and how it works to resolve the scenarios which could be contentious in a normal multi-node multi-user setup.
Some logical questions in case of a RAC database would be around the shared and common components. For example, do the nodes share storage? Do the nodes share memory? How do the nodes communicate? Since this is not a RAC study guide, answering all such questions is out of scope for this article. But one question we are definitely trying to address here is the shared memory part. Though each instance has a local buffer cache, CACHE FUSION causes sharing of cache and hence resolves the problems like concurrency etc. Needless to say, the sharing is completely transparent to the end users.
First things first - What is Cache Fusion?
Whoever knows the basics of RAC should very well be aware of the fact that CACHE FUSION is one of the most important and interesting concepts in a RAC setup. As the name suggests, CACHE FUSION is the amalgamation of cache from each node/instance participating in the RAC, but it is not any physically secured memory component which can be configured unlike the usual buffer cache (or other SGA components) which is local to each node/instance.
We know that every instance of the RAC database has its own local buffer cache which performs the usual cache functionality for that instance. Now there could be occasions when a transaction/user on instance A needs to access a data block which is being owned/locked by the other instance B. In such cases, the instance A will request instance B for that data block and hence accesses the block through the interconnect mechanism. This concept is known as CACHE FUSION where one instance can work on or access a data block in other instance’s cache via the high speed interconnect.
Cache Fusion architecture helps resolve each possible type of contentions that could be thought of in a multi-node RAC setup. We will look at them in detail in coming sections but first let us understand few very important terms/concepts which will be useful in understanding the contentions which we are going to discuss in later sections.
Global Cache Service
Global Cache Service (GCS) is the heart of Cache Fusion concept. It is through GCS that data integrity in RAC is maintained when more than one instance need a particular data block. Instances look up to the GCS for fulfilling their data block needs.
GCS is responsible for:
- Tracking the data block
- Accepting the data block requests from instances
- Informing the holding instance to release the lock on the data block or ship a CR image
- Coordinating the shipping of data blocks as needed between the instance through the interconnect
- Informing the instances to keep or discard PIs
More about the above functions will be clear from the following discussion on contention. Please note that GCS is available in the form of the background process called LMS.
Past Image
The concept of Past Image is very specific to RAC setup. Consider an instance holding exclusive lock on a data block for updates. If some other instance in the RAC needs the block, the holding instance can send the block to the requesting instance (instead of writing it to disk) by keeping a PI (Past Image) of the block in its buffer cache. Basically, PI is the copy of the data block before the block is written to the disk.
- There can be more than one PI of the block at a time across the instances. In case there is some instance crash/failure in the RAC and a recovery is required, Oracle is able to re-construct the block using these Past Images from all the instances.
- When a block is written to the disk, all Past Images of that block across the instances are discarded. GCS informs all the instances to do this. At this time, the redo logs containing the redo for that data block can also be overwritten because they are no longer needed for recovery.
A consistent read is needed when a particular block is being accessed/modified by transaction T1 and at the same time another transaction T2 tries to access/read the block. If T1 has not been committed, T2 needs a consistent read (consistent to the non-modified state of the database) copy of the block to move ahead. A CR copy is created using the UNDO data for that block. A sample series of steps for a CR in a normal setup would be:
- Process tries to read a data block
- Finds an active transaction in the block
- Then checks the UNDO segment to see if the transaction has been committed or not
- If the transaction has been committed, it creates the REDO records and reads the block
- If the transaction has not been committed, it creates a CR block for itself using the UNDO/ROLLBACK information.
- Creating a CR image in RAC is a bit different and can come with some I/O overheads. This is because the UNDO could be spread across instances and hence to build a CR copy of the block, the instance might has to visit UNDO segments on other instances and hence perform certain extra I/O
As mentioned above, CACHE FUSION helps resolve all the possible contentions that could happen between instances in a RAC setup. There are 3 possible contentions in a RAC setup which we are going to discuss in detail here with a mention of cache fusion where ever applicable.
Our discussion thus far should help understand the following discussion on contentions and their resolutions better.
- Read/Read contention: Read-Read contention might not be a problem at all because the table/row will be in a shared lock mode for both transactions and none of them is trying an exclusive lock anyways.
- Read/Write contention: This one is interesting.
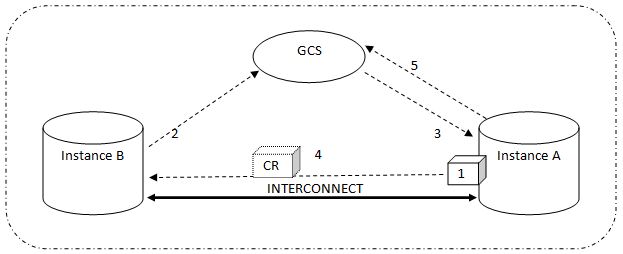
Here is more about this contention and how the concept of cache fusion helps resolve this contention - A data block is in the buffer cache of instance A and is being updated. An exclusive lock has been acquired on it.
- After some time instance B is interested in reading that same data block and hence sends a request to GCS. So far so good – Read/Write contention has been induced
- GCS checks the availability of that data block and finds that instance A has acquired an exclusive lock. Hence, GCS asks instance A to release the block for instance B.
- Now there are two options – either instance A releases the lock on that block (if it no longer needs it) and lets instance B read the block from the disk OR instance A creates a CR image of the block in its own buffer cache and ships it to the requesting instance via interconnect
- The holding instance notifies the GCS accordingly (if the lock has been released or the CR image has been shipped)
- Creation of CR image, shipping it to the requesting instance and involvement of GCS is where CACHE FUSION comes into play
- Write/Write contention:
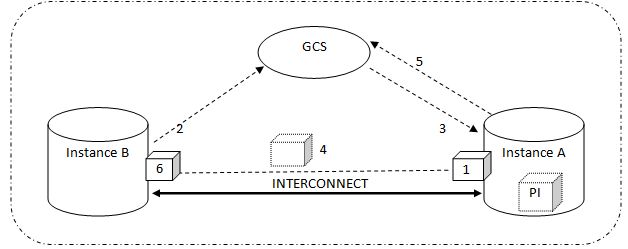
This is the case where both instance A as well as B are trying to acquire an exclusive lock on the data block. A data block is in the buffer cache of instance A and is being updated. An exclusive lock has been acquired on it
- Instance B send the data block request to the GCS
- GCS checks the availability of that data block and finds that instance A has acquired an exclusive lock. Hence, GCS asks instance A to release the block for instance B
- There are 2 options - either instance A releases the lock on that block (if it no longer needs it) and lets instance B read the block from the disk OR instance A creates a PI image of the block in its own buffer cache, makes the redo entries and ships the block to the requesting instance via interconnect
- Holding instance also notifies the GCS that lock has been released and a PI has been preserved
- Instance B now acquires the exclusive lock on that block and continues with its normal processing. At this point GCS records that data block is now with instance B
- The whole mechanism of resolving this contention with the due involvement of GCS is attributed to the CACHE FUSION.
PI image VS CR image
Let us just halt and understand some basic stuff - Wondering why CR image used in Read-Write contention and PI image used in Write-Write contention? What is the difference?
- CR image was shipped to avoid Read-Write type of contention because the requesting instance doesn’t wants to perform a write operation and hence won’t need an exclusive lock on the block. Thus for a read operation, the CR image of the block would suffice. Whereas for Write-Write contention, the requesting instance also needs to acquire an exclusive lock on the data block. So to acquire the lock for write operations, it would need the actual block and not the CR image. The holding instance hence sends the actual block but is liable to keep the PI of the block until the block has been written to the disk. So if there is any instance failure or crash, Oracle is able to build the block using the PI from across the RAC instances (there could be more than on PI of a data block before the block has actually been written to the disk). Once the block is written to the disk, it won’t need a recovery in case of a crash and hence associated PIs can be discarded.
- Another difference of course is that the CR image is to be shipped to the requesting instance where as the PI has to be kept by the holding instance after shipping the actual block.
What about UNDO?
This discussion is not about UNDO management in RAC but here is a brief about UNDO in a RAC scenario. UNDO is generated separately on each instance just similar to a standalone database. Each instance has its own UNDO tablespace. The UNDO data of all instances is used by holding instance to build CR image in case of contention
No comments:
Post a Comment